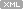
소스상에서 그대로 구현해서 쓰는 간단한 토큰.....[원본]
void Tokenize(const string& str,
vector<string>& tokens,
const string& delimiters = " ")
{
// Skip delimiters at beginning.
string::size_type lastPos = str.find_first_not_of(delimiters, 0);
// Find first "non-delimiter".
string::size_type pos = str.find_first_of(delimiters, lastPos);
while (string::npos != pos || string::npos != lastPos)
{
// Found a token, add it to the vector.
tokens.push_back(str.substr(lastPos, pos - lastPos));
// Skip delimiters. Note the "not_of"
lastPos = str.find_first_not_of(delimiters, pos);
// Find next "non-delimiter"
pos = str.find_first_of(delimiters, lastPos);
}
}
The tokenizer can be used in this way:
#include <string>
#include <algorithm>
#include <vector>
using namespace std;
int main()
{
vector<string> tokens;
string str("Split me up! Word1 Word2 Word3.");
Tokenize(str, tokens);
copy(tokens.begin(), tokens.end(), ostream_iterator<string>(cout, ", "));
}
The above code will use the Tokenize function, take the first argument str and split it up. And because we didn't supply a third parameter to the function, it will use the default delimiter " ", that is - a whitespace. All elements will be inserted into the vector tokens we created.
In the end we copy() the whole vector to standard out, just to see the contents of the vector on the screen.
Another approach is to let stringstreams do the work. streams in C++ have the special ability, that they read until a whitespace, meaning the following code works if you only want to split on spaces:
#include <vector>
#include <string>
#include <sstream>
using namespace std;
int main()
{
string str("Split me by whitespaces");
string buf; // Have a buffer string
stringstream ss(str); // Insert the string into a stream
vector<string> tokens; // Create vector to hold our words
while (ss >> buf)
tokens.push_back(buf);
}

